데이터베이스 정규화
- 데이터베이스의 품질을 측정하는 기준:
- attribute semantics를 명확히 한다.
- 튜플의 중복된 정보를 최소화한다.
- 튜플의 NULL 값을 최소화한다.
- 위변조 튜플의 생성을 방지한다.
- 각 튜플은 하나의 엔티티나 릴레이션십 인스턴스를 표현해야 함.
Redundancy
- 중복 데이터는 저장 공간을 낭비.
- Insertion anomalies
- Deletion anomalies: 한 레코드를 지우려면 중복된 모든 레코드를 제거해야.
- Update anomalies: 레코드의 내용을 변경하려면 중복된 모든 레코드를 변경해야.
Null values
- NULL은 다양한 의미를 가짐.
- 테이블을 분리하면 NULL을 없앨 수 있다. (NULL 대신 아예 레코드가 없게 됨)
- spurious tuples:
- 실제로 존재하지 않는 fake record.
- 조인을 잘못하면 spurious tuple이 생길 수 있음.
Functional Dependencies (FD)
- relational design의 일반화된 formal measures of the goodness.
- X가 Y를 functionally determine한다: X의 값이 Y의 유니크한 값을 결정하는 경우.
- e.g., 학번이 같으면 이름이 같다.
- FD는 존재할 수 있다(may exist)고 표현. 반례를 찾으면 존재하지 않는다(do not exist).
- 테이블을 보고 FD가 존재할 수 있는지, 존재하지 않는지 판단할 수 있어야.
Normalization
- ‘나쁜’ 릴레이션을 쪼개 어트리뷰트들을 작은 릴레이션으로 나누는 것.
- Normal Forms (NF):
- 포함관계: BCNF ⊂ 3NF ⊂ 2NF ⊂ 1NF.
- prime attribute: 후보키의 일부여야 한다.
- nonprime attribute: prime attribute가 아닌 것들. 후보키의 일부도 아님.
- decomposition할 때는 뭘로 조인할건지 고민해보면 된다.
1st NF
- 모든 어트리뷰트가 키에 의존하는 형식.
- composite attr, nested attr, multivalued relation이 없다면 1NF.
- 별도 릴레이션으로 분리하거나, 컬럼을 추가함으로써 해결할 수 있음.
2nd NF
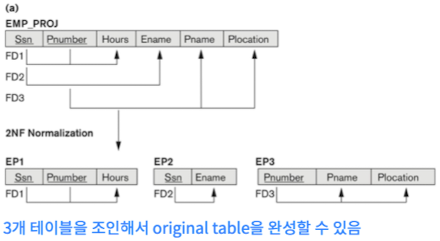
- 모든 non-prime attr이 PK에 Fully FD한 형식.
- 더 일반화된 정의: 모든 non-prime attr이 모든 키에 Fully FD한 형식.
- PK가 진짜 prime한 것만으로 구성되어 있는가?
- Full FD: e.g., (Ssn, Pnumber) → Hours. Ssn → Hours, Pnumber → Hours 둘 다 표현할 수 없으므로.
- Not a Full FD (Partial dependency): e.g., (Ssn , Pnumber) → Ename. Ssn → Ename으로 표현할 수 있으므로.
- PK의 일부가 non-prime attr을 결정해서는 안 됨.
- 1NF를 만족한다.
3rd NF
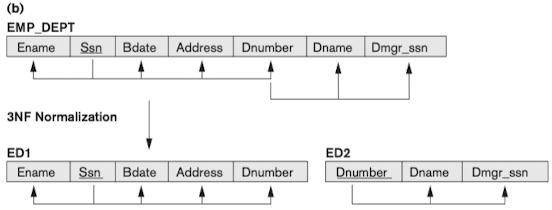
- 어떠한 non-prime attr도 PK에 대해 transitively dependent하지 않은 형식.
- Transitive FD: X→Z는 두 FD, X→Y와 Y→Z로 유도할 수 있다.
- transitive하다면 테이블을 분리할 수 있음.
- FD 관계 X → A 에서 X가 SK이거나, A가 prime attr이라면 3NF를 만족한다.
- non-prime attr이 다른 non-prime attr을 결정해서는 안 됨.
- 1NF와 2NF를 만족한다.
BCNF
- FD X → A에서 X가 SK인 형식.
- 키가 아닌 어트리뷰트가 결정자 역할을 한다면 분리해야 한다.
- N개 컬럼에 대해 decomposition 방법이 N개가 있을 수 있다.
- non-prime attr이 prime attr을 결정해서는 안 됨.
- 1NF, 2NF, 3NF를 만족한다.
이 문서를 인용한 문서