『Computer Organization and Design』
Computer Abstractions and Technology
Opening the Box
- datapath: 산술 연산을 수행하는 프로세서의 컴포넌트.
- control: 프로그램의 인스트럭션에 따라 datapath, memory 등에 명령을 내리는 프로세스 컴포넌트.
- ISA: 하드웨어와 로우레벨 소프트웨어 사이 인터페이스.
- ABI: Application Binary Interface. user instruction set + OS interface.
Performance
- response time은 '일정 양을 얼마나 빨리 처리할 수 있는가?'에 대한 것.
- throughput은 '일정 시간 동안 얼마나 많이 처리할 수 있는가?'에 대한 것.
execution time(B) / execution time(A)만약 A 컴퓨터가 명령을 수행할 때 10초가 걸리고, B가 15초가 걸린다면,15 / 10 = 1.5이므로, A 컴퓨터가 B 컴퓨터보다 1.5배 빠르다고 할 수 있다.- elapsed time은 프로세싱, 입출력, 운영체제 오버헤드를 포함하는 전체 response time. CPU time은 주어진 작업만을 처리하는 데 걸리는 시간.
- CPU Performance and Its Factors: CPU time은 clock cycle과 clock rate로 결정.
CPU Time = CPU Clock Cycles * Clock Cycle Time = CPU Clock Cycles / Clock Rate Clock Rate = Clock Cycles / CPU Time Clock Cycles = CPU Times * Clock Rate- clock cycle: 회로의 전기 진동수. tick, clock tick, clock period, clock, cycle 등으로도 부른다.
- clock period: 각 clock cycle의 길이.
- Instruction Performance: 프로그램을 수행하는 데 필요한 instruction의 수가 instruction performance를 결정.
Clock Cycles = Instruction Count * CPI CPU Time = Instruction Count * CPI * Clock Cycle Time = Instruction Count * CPI / Clock Rate- CPI: Clock cycles Per Instruction: instrucion 당 필요한 평균 clock cycle.
Instructions: Language of the Computer
Arithmetic Instructions
add $t0, $s1, $s2 #t0 = s1 + s2sub $t0, $s1, $s2 #t0 = s1 * s2
Data Transfer Instructions
lw $t0, 32($s3) #$t0 = $s3[8]sw $t0, 48($s3) #A[12] = $t0
Immediate Instructions & Bit Shift Instructions
addi $s3, $s3, 4 #$s3 = $s3 + 4sll $t1, $s3, 2 #$t1 = $s3 << 2
Conditional Instructions
bne $s3, $s4, Else #if ($s3 == $s4)j Exitjal Factorialjr $ra
Procedure
- 도입부에서 stack pointer 위치를 이동시킨다:
addi $sp, $sp, -4 - 사용할 레지스터를 내림차순으로 백업한다:
sw $s1, 8($sp) - 마지막엔 레지스터를 복원한다:
lw $s0, 0($sp)
Arithmetic for Computers
Integer Addition & Subtraction
- 덧셈, 뺄셈 연산을 하는 하드웨어를 ALU(Arithmetic Logic Unit)이라고 한다.
- 이진수 덧셈은 단순. 올림만 잘해주면 된다.
- 뺄셈은 보수를 취해 음수를 만들고, 더하기 연산을 그대로 수행.
Integer Multiplication
- right shift와 add 연산을 조합.
- multiplier의 첫 자리가 1이면 multiplier의 상위 16비트와 multiplicand를 더해 multiplier의 상위 16비트 자리를 대체.
- 한 연산을 마치면 right shift하며, 첫 자리가 0인 경우는 연산없이 right shift.
- n비트 숫자는 n번 shift하면 연산이 종료. multiplier가 결과값.
Integer Division
- left shift와 sub 연산을 조합. 속도가 느려 사용하지 않음.
Floating Point
- 소수 표현 방법이 다양해 IEEE에서 표준을 정함.
- 첫 1비트는 S, 다음 8비트는 Exponent, 다음 23비트는 Mantissa. S는 MSB와 비슷하게 부호를 나타내며, exponent는 소수점의 위치, mantissa는 구체적인 숫자를 표현.
- exponent field에는 biased notation을 사용한다. 만약 exp가 2라면 127을 더하는 식. 하드웨어 때문.
(-1)^S * (1.Mantissa) * 2^(Exponent * 127)2003.0 = (-1)^0 * 1.011111010011 * 2^10- 0을 완벽히 나타낼 수 없으므로 Exp와 Man이 모두 0이면 0으로 취급.
- normalized form으로는 작은 수를 표현하기 힘듦. (Man의 첫 자리가 무조건 1이니까.) Exp가 0이고, Man이 0이 아니라면 normalized form이 아니라는 의미.
- denormalized form은 Man의 앞자리를 0으로 써도 상관없음. 앞자리가 옮겨진 셈이니 exp bias가 127이 아닌 126.
- Exp가 0xFF, Man이 0이면 무한대를 의미. Exp이 0xFF, Man이 0이 아니라면 NaN을 의미.
- 0 / 0110 1000 / 101 0101 0100 0011 0100 0010
- S: 0. positive number.
- Exp: 0110 1000. 104(dec) bias는 104 * 127 = -23.
- Man: 1.101 0101 0100 0011 0100 0010
= 1 + [1 * 2^(-1)] + [0 * 2^(-2)] + [1 * 2^(-3)] + ...= 1.0 + 0666115 - Represents:
1.666115 * 2^(-23)
MIPS Processor
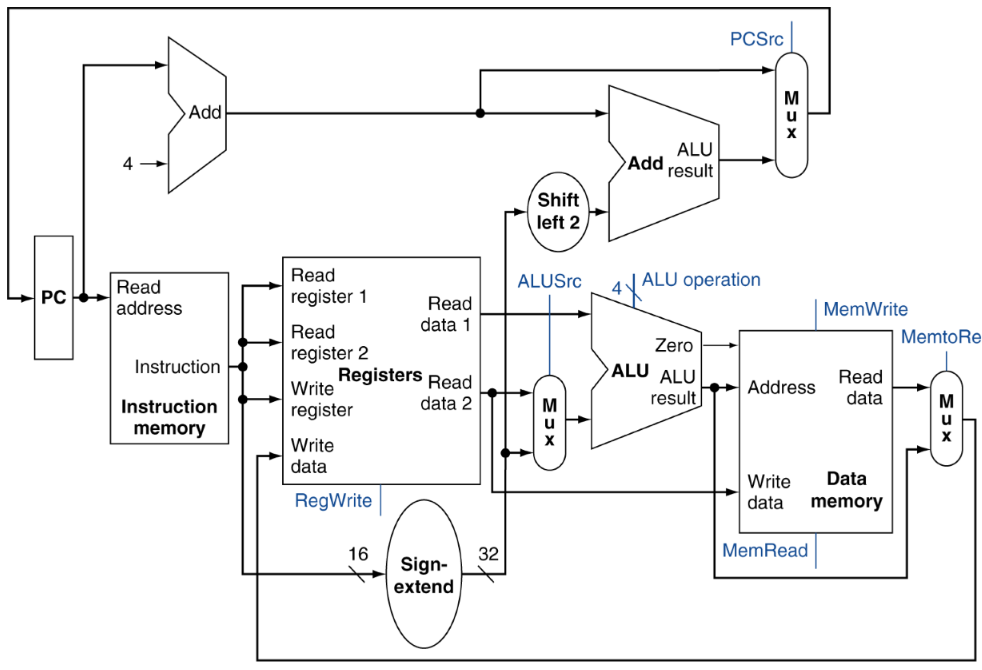
MIPS Components
- PC: 실행해야 할 instruction 위치를 가리키는 카운터.
- Instruction Memory: instruction을 fetch.
- Registers: 값을 read, write.
- ALU: 덧셈, 뺄셈 연산 수행.
- Mux: 두 입력 중 하나를 선택해 출력.
- Data Memory: 메모리에 접근해 데이터를 가져오거나 접근.
- Control: instruction을 decoding해 어떤 동작인지 signal을 보냄.
R-Format Instruction
- rs, rt, rd를 읽고 ALU에서 연산.
- register의 write data에 전달.
- write data는 rd에 값을 씌운다.
I-Format Load/Store Instructions
- rs를 읽고 register에 저장.
- offset은 Sign extend에서 32비트로 변환.
- ALU에서 rs, offset 연산하고 data memory에 전달.
- data memory가 MemWirte/MemRead signal을 보냄.
- (Load의 경우) register의 write data에 값을 보내고, rt에 값을 씌운다.
I-Format Branch Instructions
- ALU에서 rs와 rt를 빼서 0인지 확인.
- 0이라면 branch를 실행.
J-Format Jump Instructions
- register를 거치지 않고 offset을 바로 shift left 2.
- PC+4하고, PC에 반영.
Pipelining
Five Stages
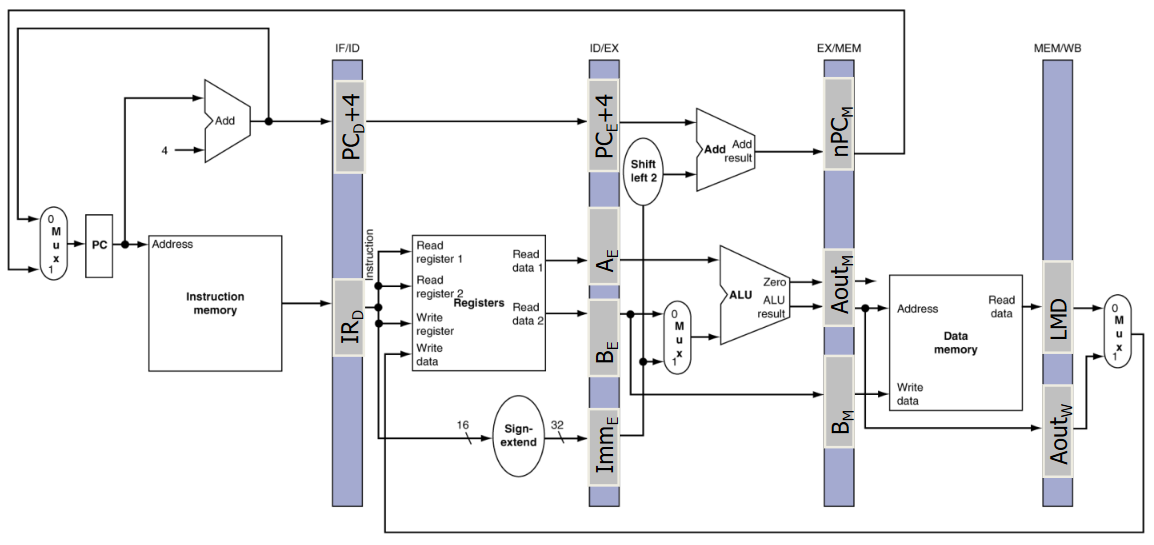
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
Pipeline Hazards
- Structural hazard: 리소스 사용에 혼란이 발생하는 경우.
- 메모리에 접근하려는데, 같은 사이클에 다른 instruction도 메모리에 접근하려는 경우.
- 메모리에는 한번에 하나의 instruction만 접근할 수 있으므로, stall을 통해 해결할 수 있다.
- Data hazard: 이전 instruction이 끝날 때까지 기다려야 하는 경우.
- forwarding을 통해 해결할 수 있다.
- ALU를 지난 즉시 값을 내려보낸다.
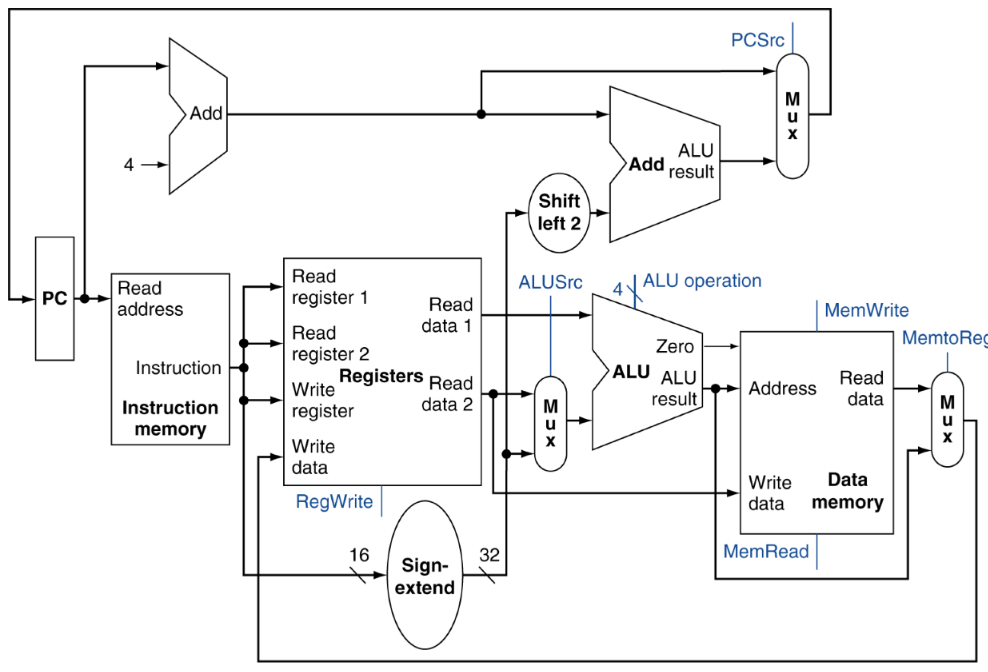
- branch instruction의 경우 앞단계의 결과를 기다려야 해서 stalled될 수 있음.
- Control hazard: 이전 instruction에 따라 control action을 결정해야 하는 경우.
- branch instruction을 해석하는 동안 하위 instruction들도 병렬적으로 처리되어 버림.
- 파이프라인에 들어왔지만 들어오지 않은 것처럼 처리해줘야 한다.
- ALU에서 branch jump 조건이 맞지 않으면 직전 instruction을 bubble로 바꾼다.
Branch Prediction
Prediction
- branch를 jump할지 말지 예측하는 것.
- history를 보고 예측한다.
- DIRP(Direction Predictor)와 **BHT(Branch History Table)**이 쓰임.
- history table의 index는 PC.
- state를 prediction으로 생각해 결과가 틀리면 state = !state한다.
- Two-bit saturating counters: 기회를 한 번 더준다.
- BTB(Branch Target Buffer): jump해야 할 위치가 어딘지 저장하는 table.
- Delayed Branching: branch prediction에 delay가 생기므로 의존성이 없는 instruction을 해당 delay cycle에서 실행하도록 최적화하는 것.
- Superscalar: 의존성이 없는 경우 한 번에 두 명령을 실행하는 것.
- Out-of-order Execution: 순서를 바꿔서 명령을 실행하는 것.
- Hardware Multithreading
Memory Hierarchy Basics
Locality
- Temporal locality: 가까운 시간 안에 다시 접근 (시간지역성)
- Spatial locality: 주변 공간에 접근 (공간지역성)
Cache
- L1 cache는 Instruction cache와 Data cache로 나뉨.
- L2 cache는 capacity를 위해 나뉘어 있지 않음.
- Miss Latency: L1 캐시에 없어서 L2 캐시에 접근하는 시간.
Miss rate = cache misses / cache accessesAverage access time = hit latency + miss rate * miss latency- 캐시가 작을수록 hit latency가 줄어든다.
- 캐시가 클수록 miss rates가 줄어든다.
- lower-level cache의 성능이 좋으면 miss latency가 줄어든다.
Hardware Cache Organization
- address의 일부 bits를 table의 index로 사용한다.
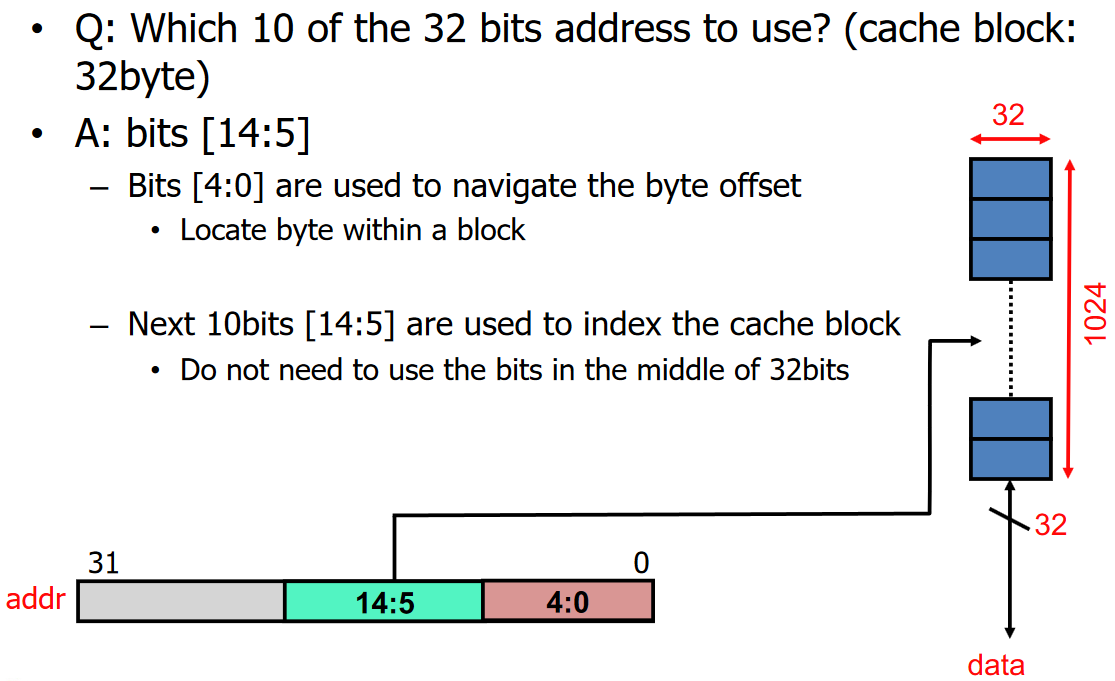
- index가 겹칠 수 있으므로 tag array가 필요하다.
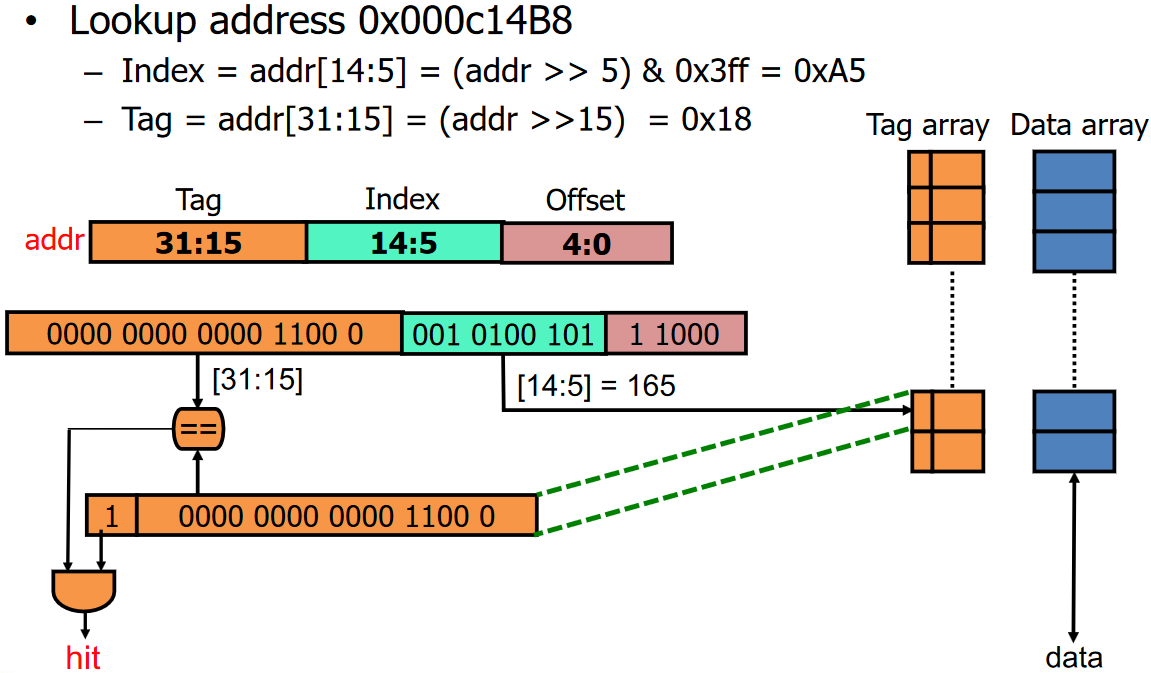
- 32KB cache는 캐시가 32KB 데이터를 저장한다는 의미.
- tag array와 data array는 병렬적으로 접근한다.
- index bit는 log2(set)으로 구할 수 있다.
Associative Cache
- Direct mapped: 들어갈 수 있는 곳이 정해져있다. (conflic가 많이 일어난다)
- Set associative: 2-way의 경우 두 곳에 들어갈 수 있다.
- Fully associative: 태그만으로 어디든 들어갈 수 있다. (속도가 느리다)
Prefetching
- 접근할 것 같은 데이터를 미리 캐시에 올려둔다.
Virtual Memory
Fragmentation
- 프로세스를 조각내 메모리 공간에 연속적이지 않도록 할당하는 것.
- 실제 메모리 주소를 생각하지 않고 한 프로세스가 전체 메모리를 사용하는 것처럼 취급.
Virtual Memory
- 각 프로세스가 각자의 가상 메모리 공간을 가지고 있음.
- virtual address를 physical address로 매핑하는 과정이 필요함.
- Demand Paging: 프로세스에도 자주 사용하는 부분이 있고, 아닌 부분이 있음. 프로세스 전체를 메모리에 올리지 않고 page를 나눠 필요한 page만 disk에서 가져와 쓴다.
- Page Fault: physical memory에 page가 없는 경우. (disk에는 있음.)
Address Translation
- address를 VPN(Virtual Page Number)와 Page offset 두 부분으로 나눔.
- virtual page number는 page table의 index로 사용.
- offset는 그대로 physical page number 뒤에 붙는다.
- virtual memory system은 address translation과 access control을 수행.
- 프로세스가 다른 프로세스의 페이지에 접근하지 못하도록 PTE에 permission bits를 추가.
- Three Major Issues
- translation & access control check 성능으로 올리려면? → TLB
- page table이 얼마나 커야하고, 어떻게 효율적으로 접근할까? → multi-level page table
- 언제 translation을 수행해야 할까?
Multi-level Page Table
- address의 VPN을 여러 개로 나누고, 테이블을 여러 개 대응시킴.
- Lv.1 이 10bits이므로 Lv.1 table은 2^10개 있음.
- Lv.1의 값은 다음 level page table의 base address.
TLB (Translation Lookaside Buffer)
- CPU와 L1 캐시 사이에 위치한 하드웨어 장치.
- PTE(Page Table Entry)를 캐시하는 역할을 한다.
- 캐시에 접근할 때 TLB를 매번 거치면 속도가 떨어지니까 캐시도 indexing, tagging을 virtual address로 하고, Processor → L1 → TLB 순서로 접근한다.
- TLB와 cache를 병렬적으로 접근할 수 있다. (L1에서만)
Virtualization
Efficient Address Translation
- VA를 PA로, 이걸 다시 SA로 변환해야 한다.
- 가상머신마다 page table이 들어가면 접근 수가 너무 많아진다.
- 많은 이슈가 있음.
Concurrency & Parallelism
Concurrency and Parallelism
- concurrency: 한 프로세서가 여러 프로세스를 timesharing하는 것.
- parallelism: 여러 코어가 한 프로세스를 나눠서 작업하는 것.
- message passing이나 shared memory로 서로 다른 프로세서가 통신할 수 있음.
Synchronization
- acquire & release (MUTEX Lock)을 통해 병렬 프로그램의 동기화를 보장할 수 있음.
- Spin lock: 소프트웨어적인 lock 구현.
- memory에서 lock를 로드하고, 잠겨있는지 확인.
- 잠겨 있다면 다시 로드를 시도하고, 열려있다면 critical section 진입.
- memory에 lock store.
- 위 과정은 시간이 오래걸려서 문제가 됨. atomic compare-and-swap (CAS) 필요.
- 하나의 instruction인 cas instruction으로 처리.
- Coarse-grain lock: 전체 DB에 하나의 lock. 쉽게 적절한 코드를 만들 수 있지만 느리다.
- Fine-grain lock: 각 레코드에 여러 개의 lock을 만들 수 있고, 빠르지만 실수하기 쉽다.
- Multiple lock: 여러개의 lock을 사용. id_from과 id_to lock을 모두 설정해야함.
- deadlock이 발생할 수 있음.’
- id가 작은 쪽이 항상 먼저 lock을 얻도록 강제하는 식으로 deadlock을 방지.
- Transactional Memory: lock이 되어 있는데 들어가면 아닌 것처럼 처리해줌.
Cache Coherence
VI Protocol
- owner 필드에 최종으로 값을 변경한 프로세서를 저장.
- private cache에 동일 데이터가 중복되지 않게 invalid시킴.
MSI Protocol
- Modified, Shared, Invalid 상태를 갖는다.
- 동시에 두 개 이상의 private cache에 데이터가 존재하면 shared
- 다른 프로세서가 데이터를 수정하면 invalid
- private cache에서 데이터를 수정한 상태라면 modified