『DDIA 5장. 복제』
- 복제란 네트워크로 연결된 여러 장비에 동일한 데이터의 복사본을 유지한다는 의미:
- 확장성: 읽기 질의를 제공하는 장비의 수를 확장해 읽기 처리량을 높인다.
- 지연시간: 데이터와 사용자의 거리를 지리적으로 가깝게 만들어 지연 시간을 줄인다.
- 내결함성/고가용성: 시스템 일부에 장애가 발생해도 지속적으로 동작할 수 있게 만들어 가용성을 높인다.
- 복제된 데이터가 시간이 지나도 변경되지 않는다면 문제가 없다:
- 복제의 모든 어려움은 복제된 데이터의 변경 처리에 있다.
- 거의 모든 분산 데이터베이스가 단일 리더, 다중 리더, 리더 없는 복제 알고리즘 중 하나를 사용한다.
리더와 팔로워
- 데이터베이스의 복사본을 저장하는 각 노드를 레플리카(replica)라고 한다.
- 복제 서버가 동일한 데이터를 유지하려면 모든 쓰기 질의가 모든 복제 서버에서 처리되어야 한다.
- 데이터 일관성 문제에 대한 일반적인 해결책은 리더 기반 복제다.
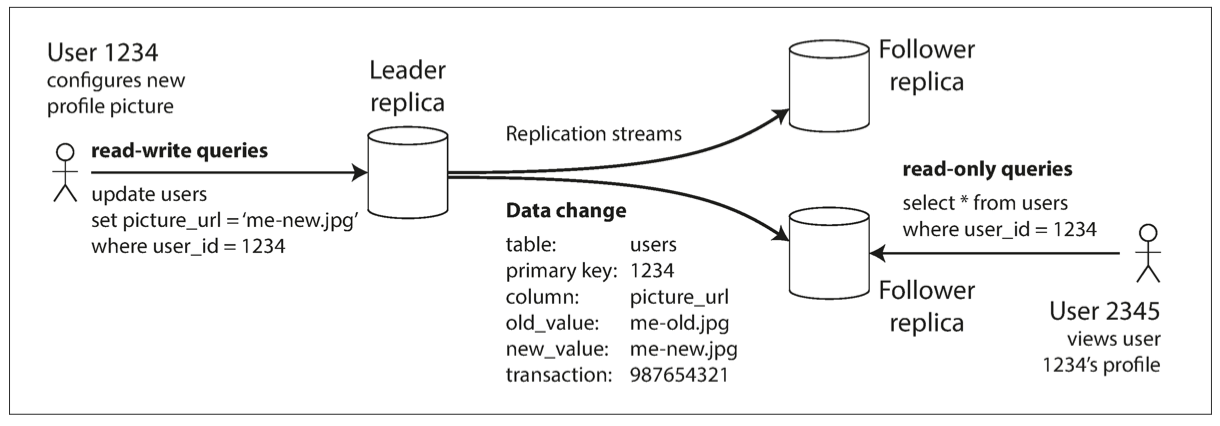
- 레플리카 중 하나를 리더로 지정한다. 클라이언트가 데이터를 변경할 때는 리더에게 질의를 보낸다.
- 또 다른 레플리카는 팔로워로 지정한다. 리더는 로컬 저장소에 새로운 데이터를 기록할 때마다 데이터 변경을 복제 로그의 일부로 팔로워에게 전송한다.
- 각 팔로워가 리더로부터 로그를 받으면 리더가 처리한 것과 동일한 순서로 업데이트를 적용해 로컬 복사본을 갱신한다.
- 클라이언트가 데이터를 읽을 때는 레플리카에게 질의할 수 있지만, 쓰기는 리더에게만 허용된다.
동기식 대 비동기식 복제
- 복제 시스템의 가장 중요한 세부 사항은 복제가 동기식으로 발생하는지 비동기식으로 발생하는지 여부다.
- 사용자가 프로필 사진을 업데이트하는 상황을 생각해보면:
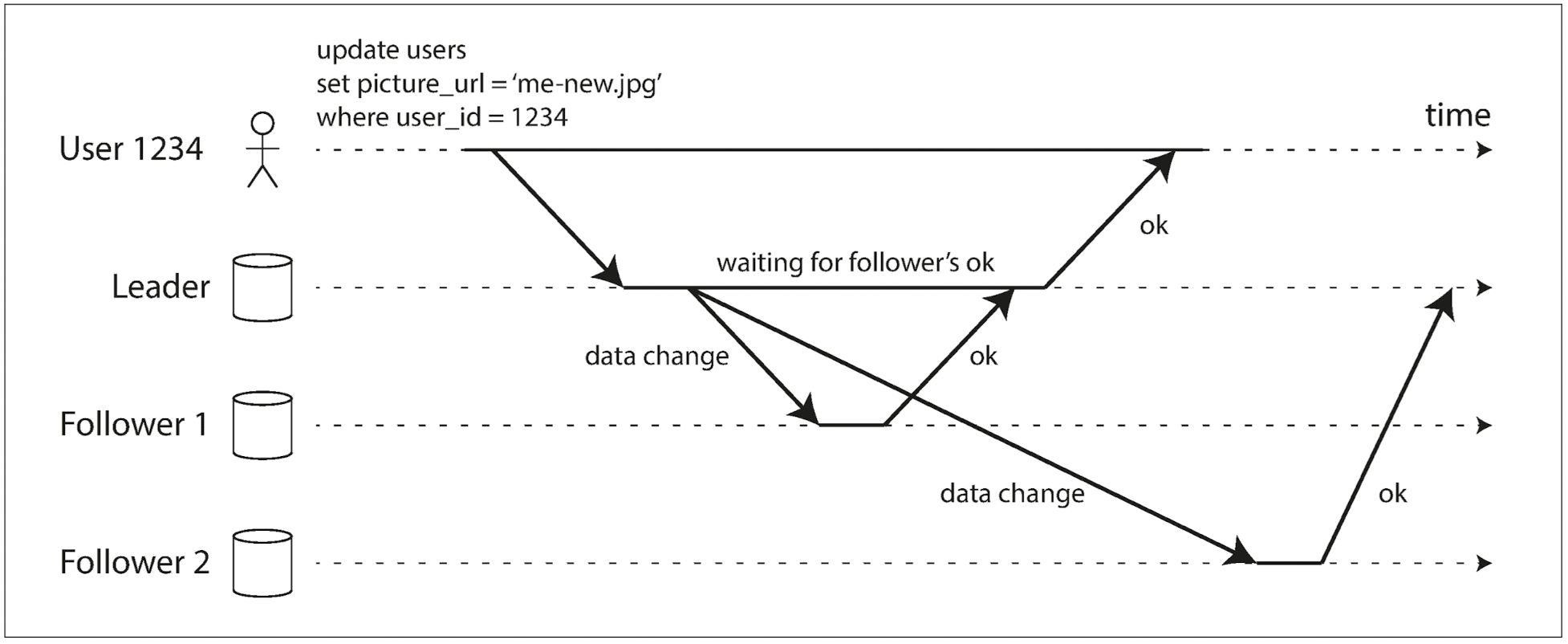
- 팔로워 1: 동기식으로 동작한다. 리더는 팔로워 1이 쓰기를 수신했는지 확인해줄 때까지 기다린다.
- 팔로워 2: 비동기식으로 동작한다. 리더는 메시지를 전송하지만 팔로워 2의 응답을 기다리지는 않는다.
- 동기식: 리더는 팔로워가 쓰기를 수신했는지 응답할 때까지 기다린다. 응답이 오면 사용자에게 성공을 응답하고, 다른 클라이언트에게 해당 쓰기를 보여준다.
- 리더와 팔로워가 일관성있게 최신 데이터 복사본을 가진다고 보장할 수 있다.
- 하지만 팔로워가 응답할 수 없는 상황에서는 쓰기 질의를 처리할 수 없다는 단점이 있다.
- 반동기식: 보통 동기식 복제를 사용한다는 것은 팔로워 하나는 동기식으로 하고, 나머지는 비동기식으로 하는 것을 의미한다. 동기식 팔로워가 사용할 수 없게되면 비동기식 팔로워 중 하나가 동기식이 되어 데이터의 일관성을 보장한다.
- 비동기식: 리더가 팔로워에게 메시지를 전송하지만 응답을 기다리지 않는다.
- 보통 리더 기반 복제는 완전히 비동기식으로 구성한다.
- 리더에 문제가 생겨 복구할 수 없게 되면 팔로워에 아직 복제되지 않은 모든 쓰기가 유실된다.
- 하지만 모든 팔로워가 잘못되더라도 리더가 쓰기 처리를 계속할 수 있다는 장점이 있다.
노드 중단 처리
- 개별 노드의 장애에도 전체 시스템이 동작하게끔 유지하고 노드 중단의 영향을 최소할 수 있어야 한다.
- 팔로워 장애: 각 팔로워는 리더의 데이터 변경 로그를 로컬 디스크에 보관한다. 팔로워가 중단되어 재시작하는 경우, 팔로워는 변경 로그에서 결함이 발생하기 전에 처리한 마지막 트랜잭션을 알아낸다. 그러면 리더와 연결이 끊어진 동안 발생한 데이터 변경을 모두 요청해 처리할 수 있다.
- 리더 장애: 리더가 죽으면 팔로워 중 하나를 리더로 승격해야 하며, 클라이어트는 새로운 리더로 쓰기를 전송하기 위해 재설정이 필요하다. 또한 다른 팔로워는 새로운 리더로부터 데이터 변경을 소비해야 한다. 이 과정을 장애 복구(failover)라 한다.
- 리더가 장애인지 판단한다: 장애의 원인은 너무 다양하기 때문에 대부분 타임아웃으로 장애를 판단한다.
- 새로운 리더를 선택한다: 보통 이전 리더의 최신 변경사항을 가진 레플리카가 리더로 선택된다.
- 새로운 리더를 사용하기 위해 시스템을 재설정한다.
복제 로그 구현
- 구문 기반 복제: 모든 쓰기 질의 구문을 로그에 기록한다. (MySQL 5.1 이전)
mysql> create table test (text TEXT); mysql> insert into test values ("replication"); mysql> select * from test; mysql> show binlog events ... Info: create table test (text TEXT) ... Info: insert into test values ("replication") - 쓰기 전 로그 배송: WAL(write-ahead logging), 데이터를 변경하기에 앞서 로그에 기록한다. (PostgreSQL, Oracle 등)
- 로우 기반 복제: 변경된 로우 자체를 인코딩해 로그에 기록한다. (MySQL 5.1 이후 구문 기반 복제와 함께 사용)
- 트리거 기반 복제: 데이터가 변경되면 애플리케이션 코드를 실행하도록 트리거링. (Databus, Bucardo 등)
복제 지연 문제
- 리더 기반 복제는 모든 쓰기가 단일 노드를 거쳐야 하지만, 읽기 전용 질의는 어떤 복제 서버에서도 가능하다.
- 비동기 팔로워에서 데이터를 읽을 때 팔로워가 뒤쳐진다면 업데이트되지 않은 오래된 정보를 볼 수도 있다. 쓰기를 멈추고 잠시 기다리면 팔로워는 리더를 따라잡게 되는데, 이런 효과를 최종적 일관성이라고 한다.
- 리더를 따라자는 지연이 매우 크면 불일치 문제는 이론적인 문제가 아니라 실제 문제가 된다. 이를 위해 쓰기 후 읽기 일관성(read-after-write consistency)과 단조 읽기(monotonic read)가 필요하다.
자신이 쓴 내용 읽기
- 비동기식 복제에서는 쓰기 직후 데이터를 조회한다면 새로운 데이터가 아직 레플리카에 반영되지 않았을 수 있다.
- 이때 쓰기 후 읽기 일관성이 필요하다:
- 사용자가 수정한 내용을 읽을 때는 리더에서 읽는다. SNS라면 사용자가 자신의 프로필은 항상 리더에서 읽도록 할 수 있다.
- 데이터의 갱신 후 1분 동안은 리더에서 모든 읽기를 수행한다.
- 동일한 사용자가 여러 디바이스를 사용한다면 디바이스 간 쓰기 후 읽기 일관성을 제공해야 한다:
- 한 디바이스에서 수행 중인 코드는 다른 디바이스에서 발생한 변경을 모르기 때문에 메타데이터가 중앙집중식으로 관리되어야 한다.
- 레플리카가 여러 데이터센터에 분산되어 있다면 서로 다른 디바이스의 연결을 동일한 데이터센터로 라우팅해야 한다.
단조 읽기
- 비동기식 팔로워가 겪는 또 다른 문제는 시간이 거꾸로 흐르는 현상이 발생한다는 것.
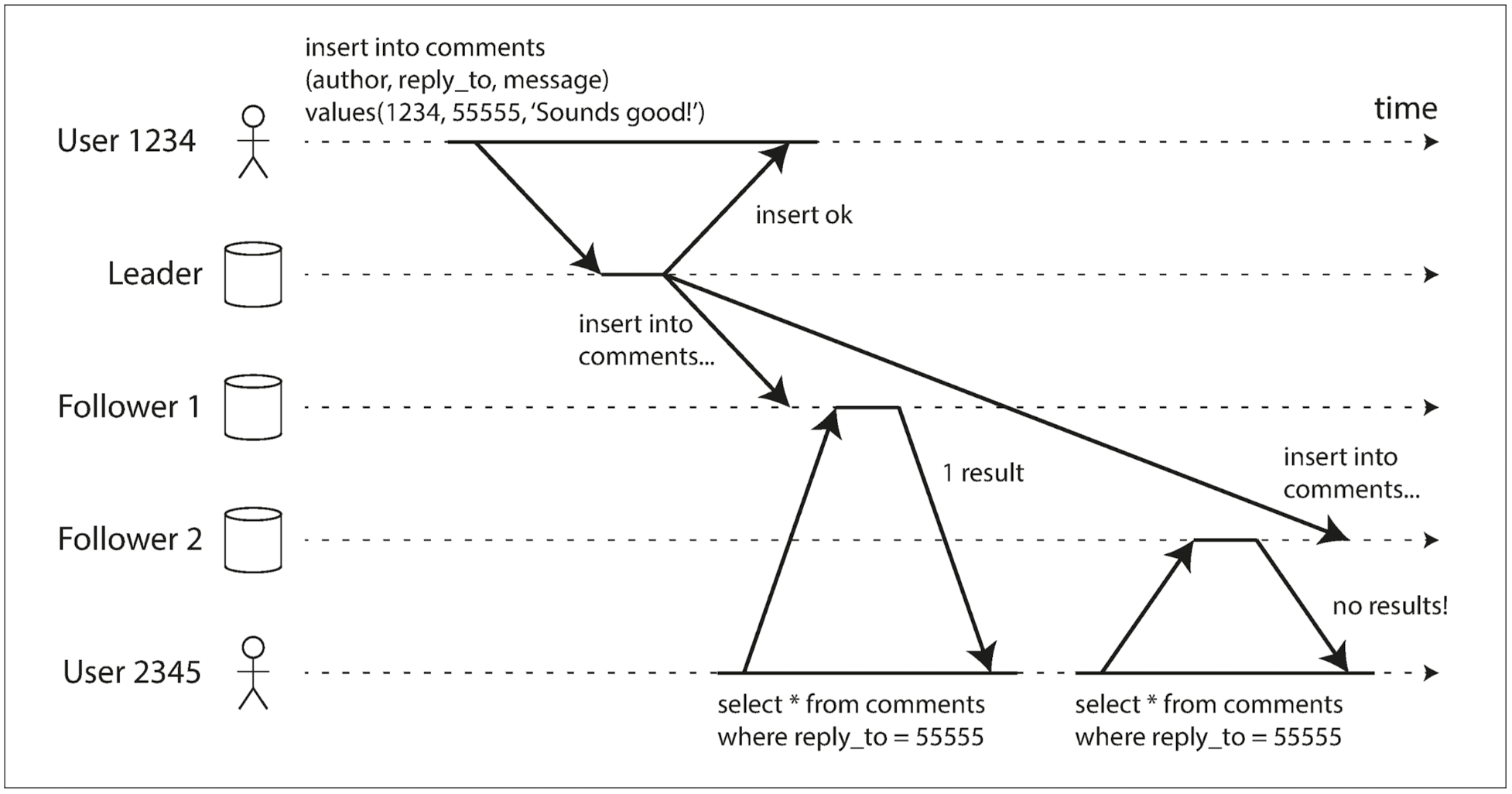
- 단조 읽기는 이런 이상 현상이 발생하지 않음을 보장한다.
- 각 사용자의 읽기가 항상 동일한 레플리카에서 수행되게끔하면 단조 읽기를 달성할 수 있다.
- 가령 사용자 ID의 해시를 기반으로 복제 서버를 선택하면 한 사용자가 항상 같은 레플리카를 읽게 된다.
다중 리더 복제
- 리더 기반 복제에서 리더에게 문제가 생기면 데이터베이스에 쓰기를 할 수 없게 되는 문제가 있다.
- 따라서 쓰기를 허용하는 노드를 하나 이상 두는 방식으로 해결하는데, 이를 다중 리더 복제라고 한다.
- 단일 데이터센터 내에 다중 리더 설정을 사용하는 것은 적절치 않지만 몇 가지 상황에서는 합리적이다:
- 다중 데이터센터: 각 데이터센터마다 리더가 있을 수 있다.
- 오프라인에서도 동작해야 하는 애플리케이션: 클라이언트의 로컬 데이터베이스가 리더처럼 동작한다.
- 협업 편집: 동시에 같은 부분을 편집할 수 있게끔 하는 동시에 충돌을 해소한다.
쓰기 충돌 다루기
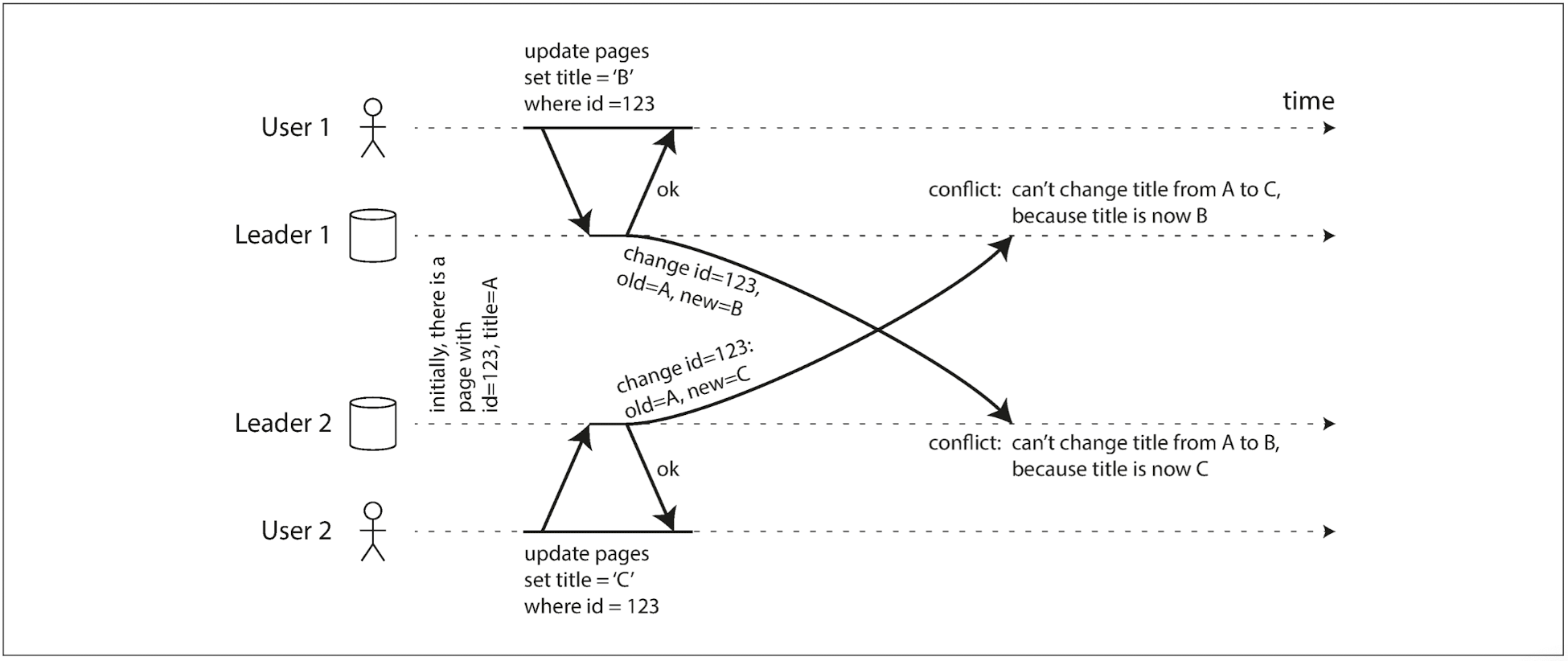
- 다중 리더 복제에서 가장 큰 문제는 쓰기 충돌이다.
- 동기식 충돌 감지: 단일 리더 복제에서는 첫 번째 쓰기가 완료될 대까지 두 번째 쓰기를 차단한다. 다중 리더 복제에서도 가능하지만, 다중 리더 복제의 장점을 잃는다.
- 충돌 회피: 특정 레코드의 모든 쓰기가 동일한 리더를 거치도록 애플리케이션이 보장한다.
- 일관된 상태 수렴: 다중 리더 복제에서는 쓰기 순서가 보장되지 않아 최종 값이 무엇인지 알 수 없다. 따라서 모든 레플리카가 최종적으로 동일하다는 것을 보장하기 위해 수렴 방식으로 충돌을 해소해야 한다.
- 각 쓰기에 고유 ID를 부여하고 가장 높은 ID를 가진 쓰기만 선택해 반영한다.
- 각 레플리카에 고유 ID를 부여하고 높은 숫자의 레플리카의 쓰기를 항상 우선 반영한다.
- 값을 병합한다. 사전순으로 정렬해 병합한다면 위 그림에서는 제목이 "B/C"가 된다.
- 명시적 데이터 구조에 충돌을 기록해 모든 정보를 기록한다.
- 사용자 정의 충돌 해소 로직: 대부분의 다중 리더 복제 도구는 애플리케이션 코드를 사용해 충돌 해소 로직을 작성한다.
- 자동 충돌 해소 로직: CRDT(onflict-free replicated datatype)[1], Git과 같은 three-way 병합 함수, OP(operational transform)[2] 등.
다중 리더 복제 토폴로지
- 쓰기를 한 노드에서 다른 노드로 전달하는 통신 경로.
- 리더가 둘 이상이라면 다양한 토폴로지가 가능하다:
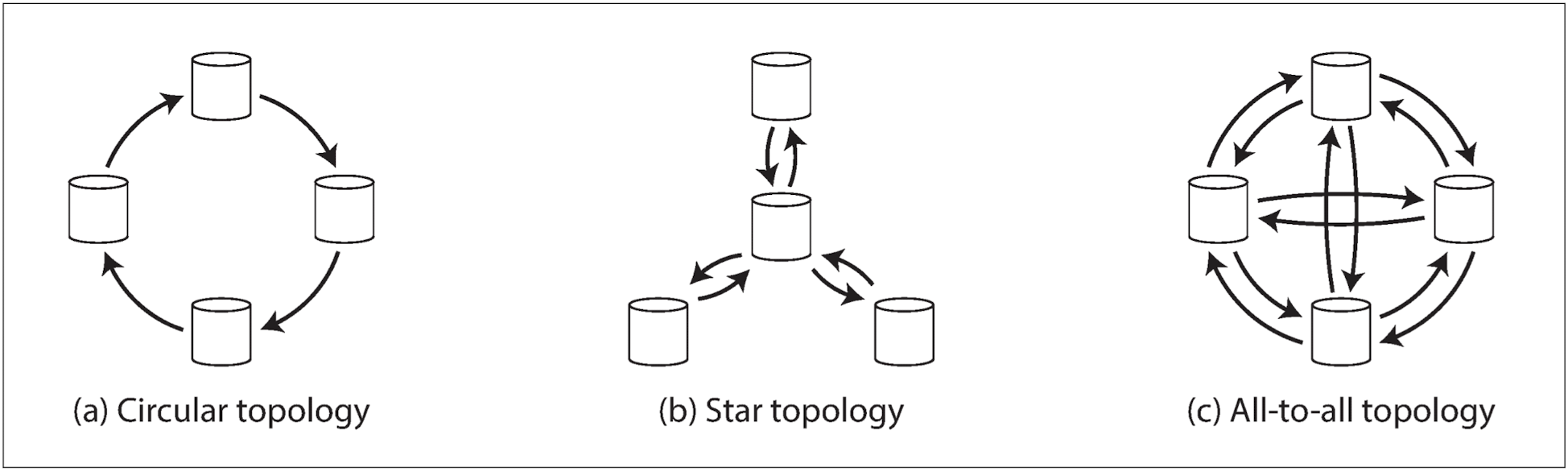
- circular: 각 노드가 하나의 노드로부터 쓰기를 받고, 하나의 노드에게 쓰기를 전달한다.
- star: 지정된 루트 노드 하나가 다른 모든 노드에게 쓰기를 전달한다.
- all-to-all: 가장 일반적인 토폴로지. 모든 리더가 각자의 쓰기를 다른 모든 리더에게 전송한다.
- 다중 리더 복제에서는 네트워크 혼잡 등의 이유로 일부 레플리카에 쓰기가 잘못된 순서로 도착할 수 있다:
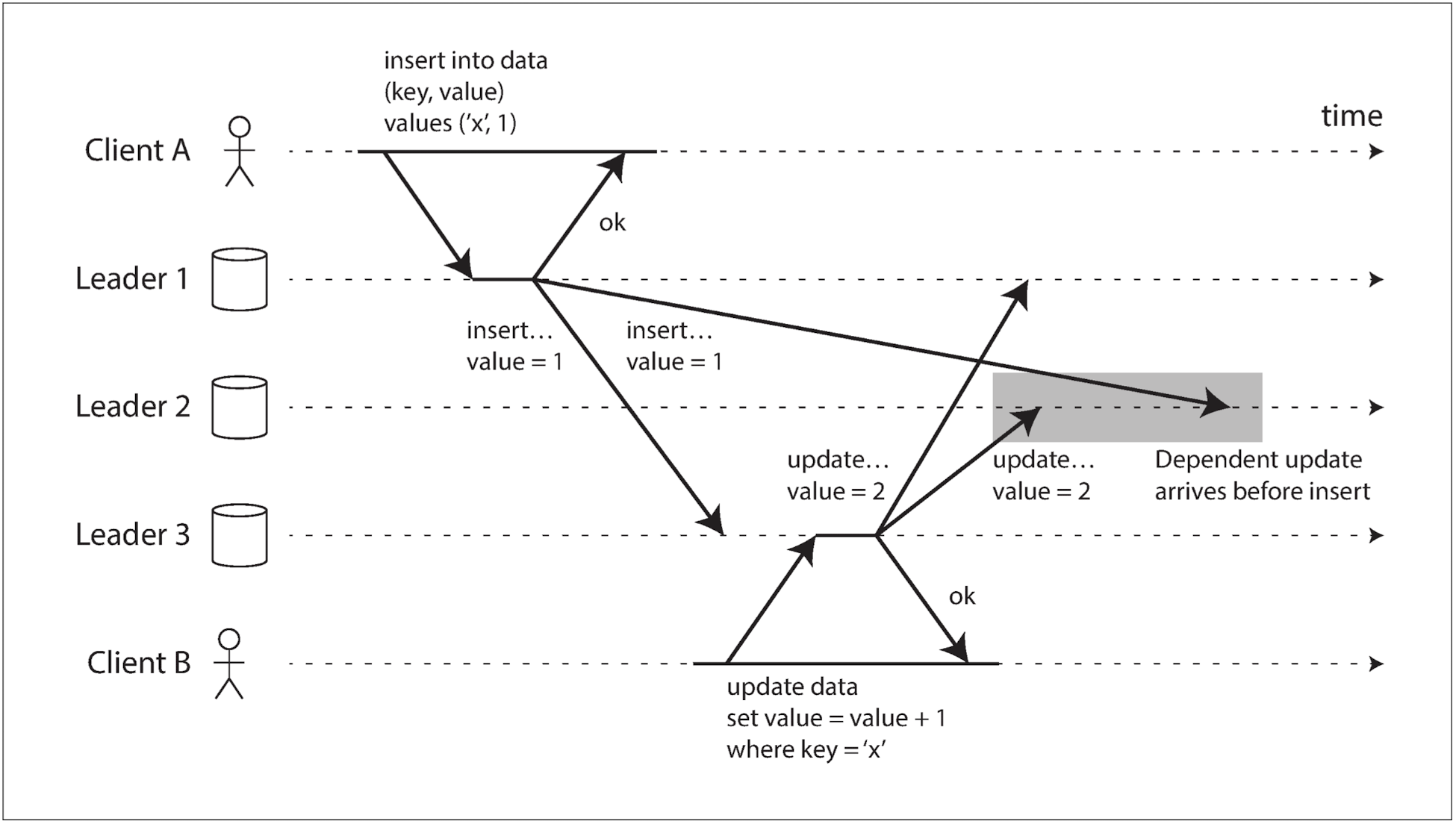
- 실제로는 클라이언트 A가 insert한 다음 B가 update를 했지만, 리더 2에게는 그 순서가 반대로 도착한다.
- 이런 문제를 해결하기 위해 버전 벡터를 사용할 수 있다.
- 많은 다중 리더 복제 시스템이 충돌 감지 기법을 제대로 구현하지 않고 있기 때문에 실제로 믿을 만한 보장을 하는지 확인하는 편이 좋다.
리더 없는 복제
- 리더 없이 모든 레플리카가 쓰기를 직접 처리하는 복제 시스템.
- 초기 복제 데이터 시스템이 이러했으나, RDB가 우세하며 잊혀졌다.
- 이후 아마존이 다이나모 시스템에 사용하며 다시 유행했다. 리악, 카산드라, 볼드모트가 리더 없는 복제 모델을 사용하며, 이러한 데이터베이스를 다이나모 스타일이라고 한다.
노드가 다운됐을 때 데이터베이스에 쓰기
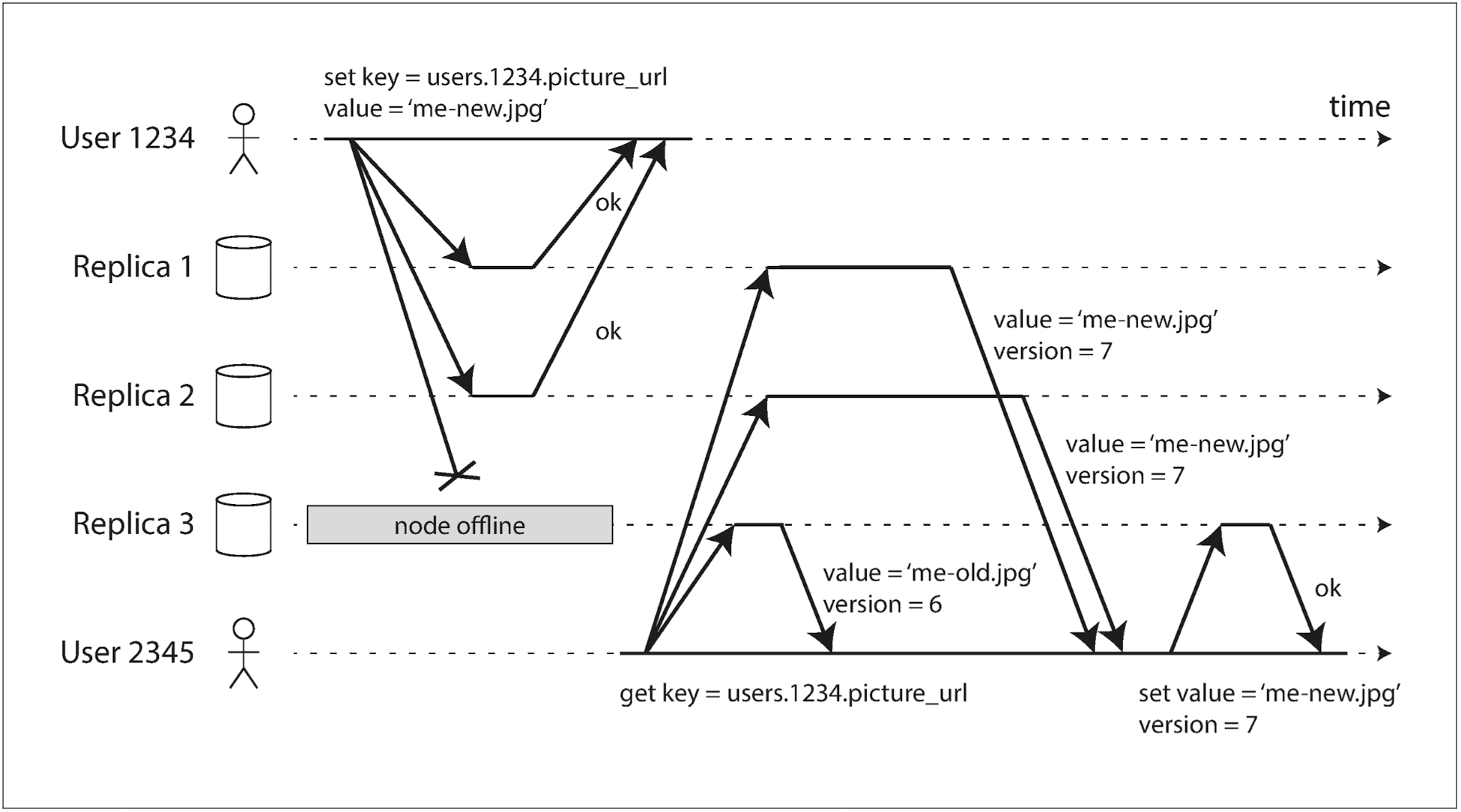
- 리더가 없다면 레플리카 하나에 문제가 생겨도 장애 복구가 필요하지 않다.
- 레플리카 3이 오프라인이 됐지만 다른 레플리카에서 쓰기 처리를 하므로 문제가 되지 않는다.
- 하지만 이후 레플리카 3이 복구된 시점에 데이터는 변경이 누락되어 오래되었을 수 있다.
- 다이나모 스타일 데이터스토어는 이를 해결하기 위해 두 가지 방법을 사용한다:
- 읽기 복구: 클라이언트가 여러 노드에 읽기 질의를 병렬적으로 보내고, 응답 중 버전 숫자가 가장 최신인 데이터를 선택한다. 이때 오래된 데이터는 새롭게 업데이트한다.
- 안티 엔트로피 처리: 백그라운드 프로세스를 두고 노드 사이 데이터 차이를 지속적으로 찾아 오래된 데이터를 업데이트한다.
읽기와 쓰기를 위한 정족수
- 모든 성공한 쓰기가 세 개의 레플리카 중 적어도 두 개의 레플리카에 존재한다는 것을 보장한다면 나머지 하나의 레플리카가 오래된 데이터라고 볼 수 있다.
- 따라서 셋 중 하나의 레플리카에 문제가 생겨도 두 개의 레플리카에서 데이터를 읽으면 둘 중 적어도 하나는 최신 값임을 기대할 수 있다.
- 이를 일반화하면:
개의 레플리카가 있을 때 모든 쓰기는 개의 노드에서 성공해야 쓰기가 확정된다. - 모든 읽기는 최소한
개의 노드에 질의해야 한다. 이때 이면 최신 값을 얻을 것으로 기대한다. - 이런
과 를 따르는 읽기, 쓰기를 정족수 읽기, 쓰기라고 부른다. 유효한 읽기와 쓰기를 위해 필요한 최소 득표수를 과 라고 할 수 있다.
- 이 방식을 엄격한 정족수(strict quorum)이라고 한다.
정족수 일관성의 한계
과 가 작을수록 오래된 값을 읽을 확률이 높다. 일 때도 오래된 값을 얻는 엣지 케이스가 있다. - 견고하게 일관성을 보장하려면 트랜잭션이나 합의 알고리즘이 필요하다.
느슨한 정족수와 암시된 핸드오프
- 네트워크 문제로
또는 이상의 노드가 오프라인이 되면 정족수를 충족할 수 없게 된다. - 이때 데이터베이스 설계자는 트레이드오프에 직면한다:
- 정족수를 만족하지 않는 모든 요청에 대해 오류를 반환할 것인가?
- 일단 쓰기를 받아들이고,
개 노드에 속하지 않지만 온라인인 노드에 기록할 것인가? → 느슨한 정족수 (sloppy quorum) - 네트워크가 정상화되면 임시로 수용한 모든 쓰기를
개의 홈 노드로 전송한다. 이 방식을 암시된 핸드오프(hinted handoff)라고 한다. - 쓰기 가용성을 높일 수 있지만, 암시된 핸드오프가 완료될 때까지는 최신 데이터를 읽는다고 보장할 수 없다.
- 네트워크가 정상화되면 임시로 수용한 모든 쓰기를
동시 쓰기 감지
- 클라이언트가 동시에 같은 데이터에 쓰기를 할 수 있다.
- 네트워크 문제로 이벤트가 서로 다른 노드에 다른 순서로 요청이 도착할 수 있다:
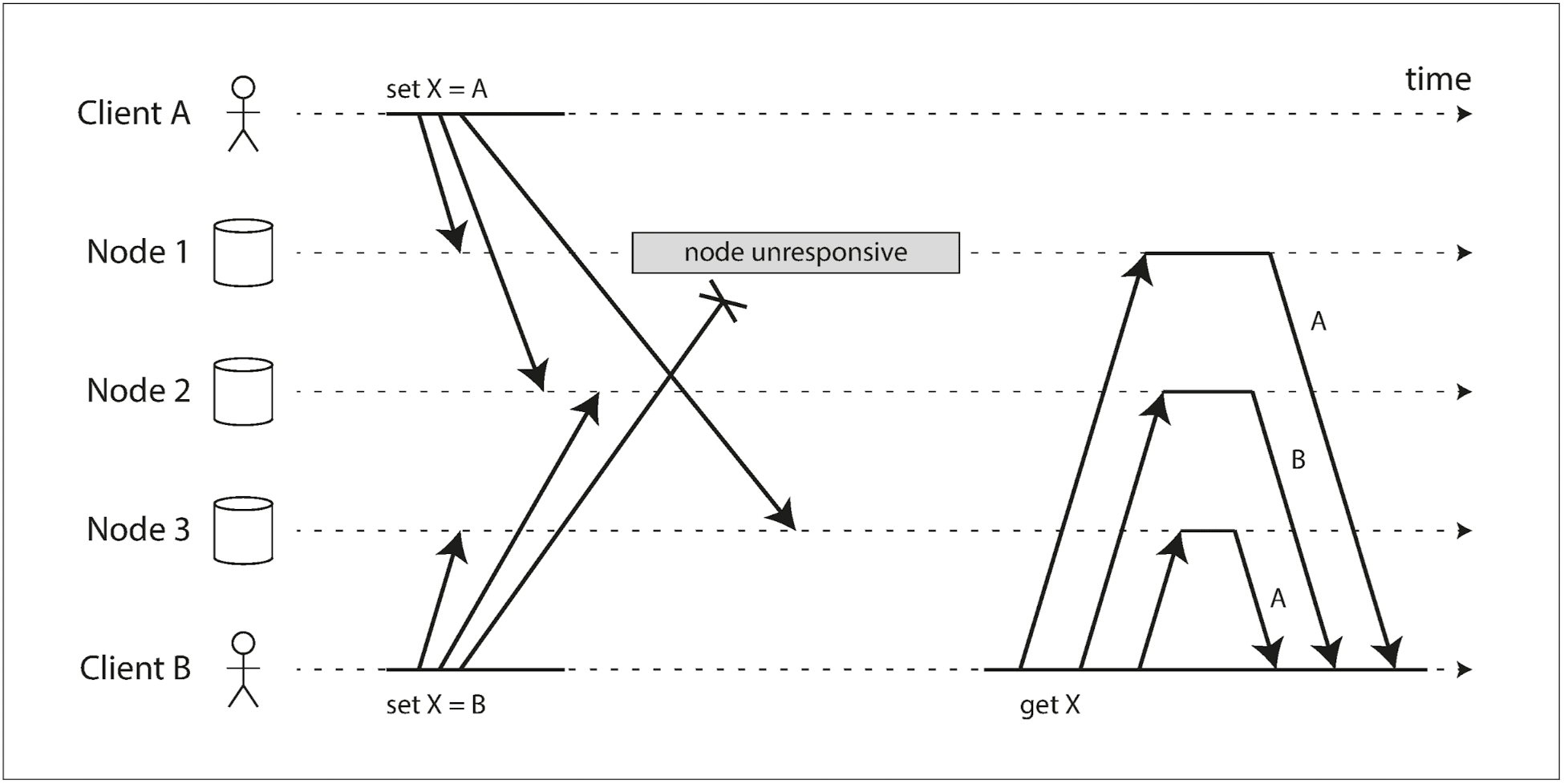
- 노드 1: A에게 쓰기를 받지만 순간적인 상애로 B의 쓰기를 받지 못함. (
X = A) - 노드 2: A에게 쓰기를 먼저 받은 다음 B의 쓰기를 받는다. (
X = B) - 노드 3: B에게 쓰기를 먼저 받은 다음 A의 쓰기를 받는다. (
X = A)
- 노드 1: A에게 쓰기를 받지만 순간적인 상애로 B의 쓰기를 받지 못함. (
- 각 노드가 쓰기 요청을 받을 때마다 값을 덮어 쓴다면 노드들의 일관성이 영구적으로 깨진다.
- 최종 쓰기 승리(LWW): 쓰기에 타임스탬프를 붙여 가장 최신인 것만 반영한다.
- 두 작업이 동시에 수행됐는지 여부를 어떻게 결정할까?
- 작업 B가 작업 A에 대해 알거나, A에 의존적이거나, A를 기반으로 한다면 작업 A는 B의 이전 발생(happens-before)이다.
- 한 작업이 다른 작업 이전에 발생했는지가 동시성의 의미를 정의하는 핵심이며, 어느 작업도 다른 작업을 알지 못하면 단순히 동시 작업이라고 말한다.[3]
- 동시성을 정의하는 데 두 작업이 정말 ‘같은 시각에’ 발생했는지는 중요하지 않다. 두 작업이 서로 알지 못하면 두 작업은 동시에 수행됐다고 한다.
이전 발생 관계 파악하기
- 단일 복제본에서 어떻게 두 작업의 동시 발생 여부를 알 수 있는지 보면 다중 복제본 데이터베이스에 대한 접근 방식을 일반화할 수 있다.
- 두 클라이언트가 같은 장바구니에 상품을 추가한다고 가정하자:
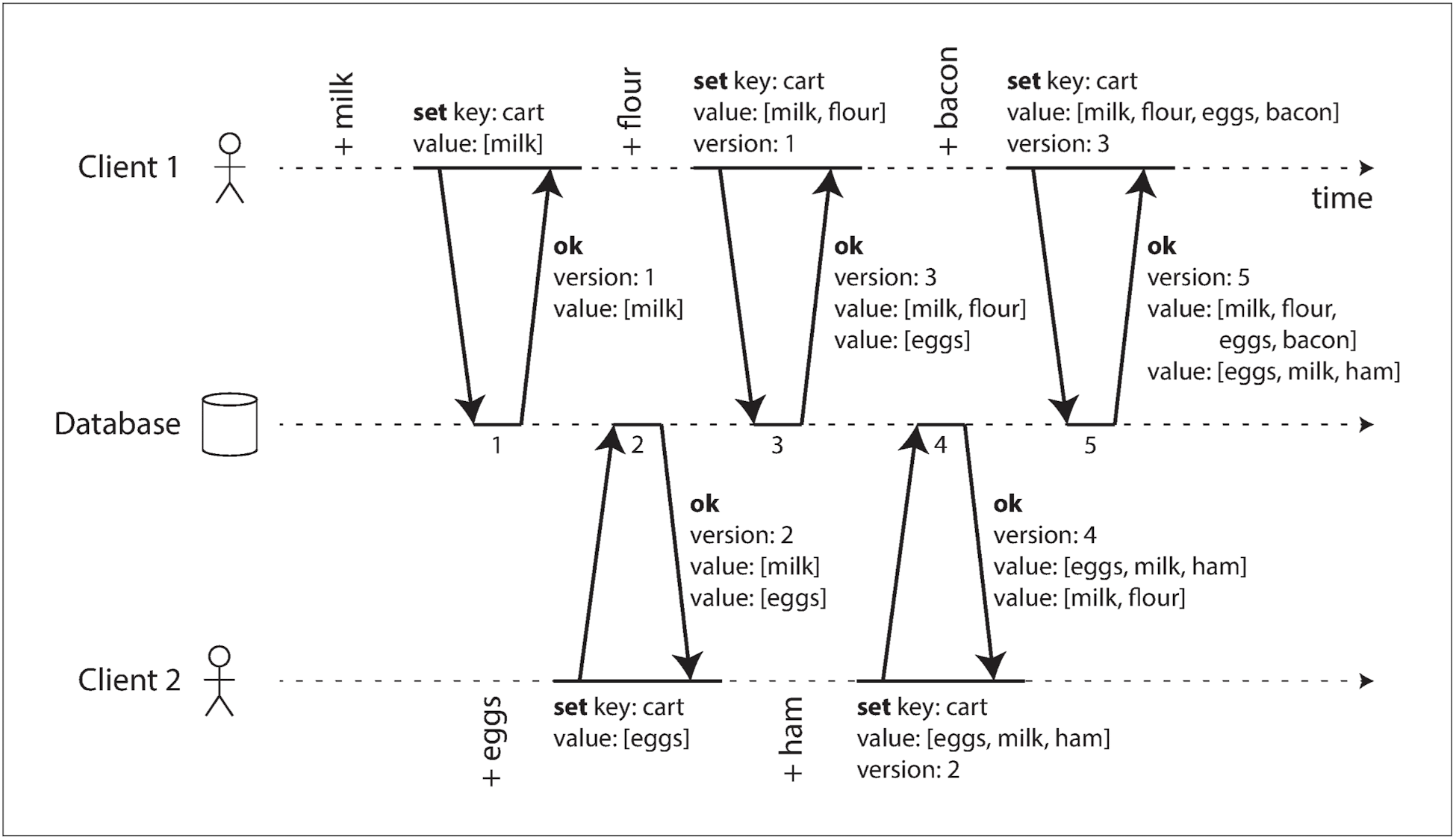
- 클라이언트 1: 장바구니에 우유를 추가하고, 우유가 추가됐다는 것을 확인한다.
- 클라이언트 2: 장바구니에 우유가 있다는 사실을 모르는 상태에서 달걀을 추가한다.
- 클라이언트 1: 장바구니에 달걀이 추가됐다는 사실을 모르는 상태에서 밀가루를 추가한다.
- 클라이언트 2: 장바구니에 밀가루가 추가됐다는 사실을 모르는 상태에서 햄을 추가한다. 이때 클라이언트 2는 앞서 서버로부터 버전 2 응답을 받았기 때문에 장바구니에 우유가 있다는 사실을 안다.
- 클라이언트 1: 베이컨을 추가한다. 이전에 서버에서 버전 3을 받았으므로, 여기에 베이컨을 추가해 요청한다.
- 아래 다이어그램에서 화살표는 어떤 작업이 다른 작업 이전에 발생했는지, 나중 작업이 이전에 수행된 작업을 알거나 의존했다는 사실을 나타낸다:
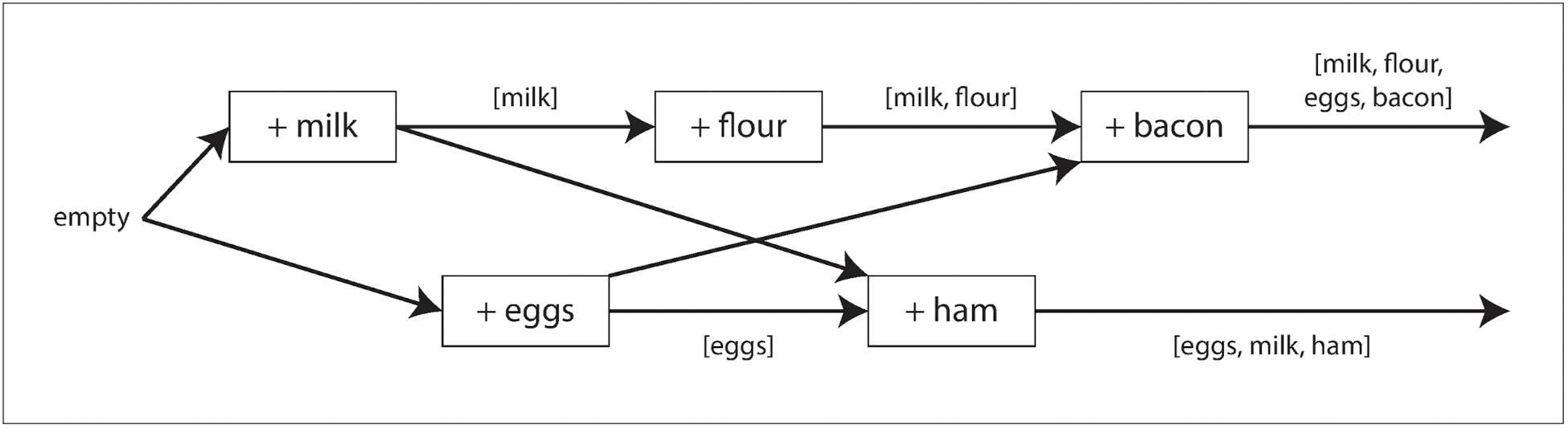
- 클라이언트는 서버와 동일한 최신 데이터를 유지하지 못하지만, 최종적으로 예전 버전 값을 덮어쓰기 때문에 손실된 쓰기는 없다.
- 서버는 키를 쓰기할 때마다 버전 번호를 올리며, 클라이언트는 키를 쓰기할 때 이전 읽기 버전 번호를 포함해서 요청한다. 서버는 버전 번호를 보고 두 작업이 동시에 수행됐는지 알 수 있다.
- 여기서는 동시에 쓴 값을 병합할 때 합집합을 취했는데, 상품을 제거하는 경우 제거한 상품이 다시 나타나는 문제가 있다. 따라서 버전 번호에 상품을 제거했음을 표시하는 툼스톤이 필요하다.
버전 벡터
- 다중 복제에서는 키당 버전 번호 뿐 아니라 복제본당 버전 번호도 필요하다.
- 모든 복제본의 버전 번호 모음을 버전 벡터라고 한다. 리악에서는 이를 변형한 도티드 버전 벡터(dotted version vector)를 사용한다.
Memo
안티 엔트로피
- 엔트로피는 쉽게 표현하면 ‘무질서도’, '무질서한 정도’를 측정하는 물리학적 양.
- 시스템의 엔트로피는 시간이 지남에 따라 점점 커진다.
- 데이터베이스에서 안티 엔트로피는 노드 간의 복제본을 동기화하고 최신 상태를 유지하는 것을 말한다.
OT / CRDT
- OT: 모든 변경에 대한 시간순 목록을 저장. 중앙 집중식 서버나 데이터베이스가 필요하다.
- CRDT: set, map, ordered list, counter 등의 데이터 타입을 사용해 자동으로 충돌을 해소하기 위한 자료 구조.
- CRDT는 중앙 데이터베이스 없이 실시간 편집이 가능하고, 속도, 용량, 기능, 복잡도 모두 개선됨.[2:1]
- A Conflict-Free Replicated JSON Datatype:[1:1]
- JSON 데이터 모델을 이용한 CRDT. 모든 쓰기를 누락시키지 않고 반영하는 것이 목적.
- 중앙 서버 없이 P2P 네트워크를 통해서 동작할 수 있는 매커니즘.
- 변경 사항을 병합하는 방식으로 동작한다. 페이퍼에 동일 키에 대한 변경, 삭제, 리스트에 대한 변경 등 구체적인 예시가 있음.
- 하지만 Figure 6처럼 모든 것을 반영하지 않고 어떤 쓰기는 버려야 하는 상황도 있다. (이 페이퍼에서는 다루지 않음.)
- 피그마의 동시 협업 기능도 CRDT 방식으로 구현했다.
동시성, 시각, 상대성
- 정보가 빛의 속도보다 빠를 수 없기 때문에 이벤트간 시간차가 빛의 속도보다 짧으면 두 이벤트는 서로 영향을 미칠 수 없다.
참고자료
- 오길원, “MariaDB Binlog을 이용한 변경사항 추적”, 리디주식회사, 2017.
- Evan Wallace, “How Figma’s multiplayer technology works”, Figma, 2019
- senna, “CRDT vs OT”, 채널톡, 2021.
이 문서를 인용한 문서
- 『데이터 중심 어플리케이션 설계(DDIA)』
-
5장. 복제
-
- Goodbye 2021
-
복제 챕터 발제를 준비하면서 CRDT에 대해 자세히 공부했는데 너무 재밌었다.
-